
모델 재현 중요성
AI 실험을 설계할 때, AI 모델은 재현이 가능하여야 한다. 그래야 다른 사람이 똑같이 실험을 했을 때, 내 실험의 결과가 거짓이 아님을 증명할 수 있고, 설계한 모델의 성능을 보장한 상태에서 재사용이 가능하다.
데이터와 모델 관계
"데이터가 바뀌면, 모델 결과도 바뀐다." ←(이)→ "데이터가 같으면, 모델 결과도 같다."
물론, 명제의 이가 언제나 참임을 보장하진 않지만, AI 모델링에선 중요한 명제이다.
실험 1 - 매번 Split할 때
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
# 1. 데이터가 같다면,
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
# 2. 모델 결과도 같아야 한다.
for i in range(10):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = XGBClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
acc_score = accuracy_score(y_test, y_pred)
print(f"{i+1}번 실험: {acc_score:.4f}")
그런데, 결과는 다르다. 왜냐면, 아래 코드가 for문 안에 들어가 있기 때문에, 매번 데이터셋을 다시 split하기 때문에 '동일한 데이터'를 보장하지 않기 때문이다. 그래서 모델 결과가 달라진다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
실험 2 - 데이터는 같지만, 스크립트를 2번 실행할 때
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
# 1. 데이터가 같다면,
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 2. 모델 결과도 같아야 한다.
for i in range(10):
clf = XGBClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
acc_score = accuracy_score(y_test, y_pred)
print(f"{i+1}번 실험: {acc_score:.4f}")
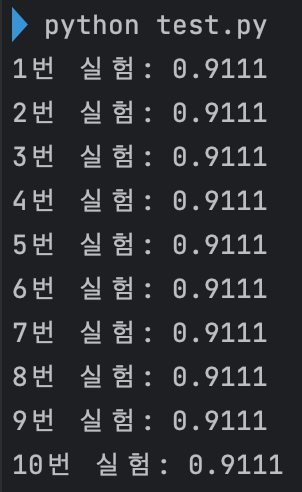
이유 - 파이썬 난수표 생성
같은 커널에서 같은 스크립트를 두 번 실행할 때, 각각 결과가 다르다. (같은 실행 안에서는 같다.)
이것은 '파이썬'이 난수를 생성하는 방법 때문에 이런 차이가 발생한다.
파이썬 프로그램이 구동되어 커널이 준비될 때, 난수표를 생성해서 갖고 있는다.
그리고, 난수 중 일부를 요청하면, 요청한 난수를 Return하고, 포인터가 이동해서 난수표 안에서 다른 곳을 가리키게 된다.
이때, 커널을 다시 실행하면 변경된 포인터에서부터 요청한 난수를 Return하게 되어 다른 값이 전달된다.
이런 이유 때문에 for문 밖으로 코드를 수정했다고 해도, 매번 실행할 때마다 난수표 포인터 이동으로 인해 '동일한 데이터'를 보장하지 않는다.
해결 방법
- 커널을 재시작하여 난수표 실행 순서를 같게 만든다. (포인터 이동 전으로 돌아가게 만드는 것)
- 난수표에서 난수 추출 순서를 지정한다. (random_state, random_seed)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
# 1. 데이터가 같다면,
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2024)
# 2. 모델 결과도 같아야 한다.
for i in range(10):
clf = XGBClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
acc_score = accuracy_score(y_test, y_pred)
print(f"{i+1}번 실험: {acc_score:.4f}")
