1. 인덱스 개념
- 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료구조
- 특정 컬럼에 인덱스를 생성하면 해당 컬럼의 데이터들을 정렬하여 별도의 공간에 데이터의 물리적 주소와 함께 저장
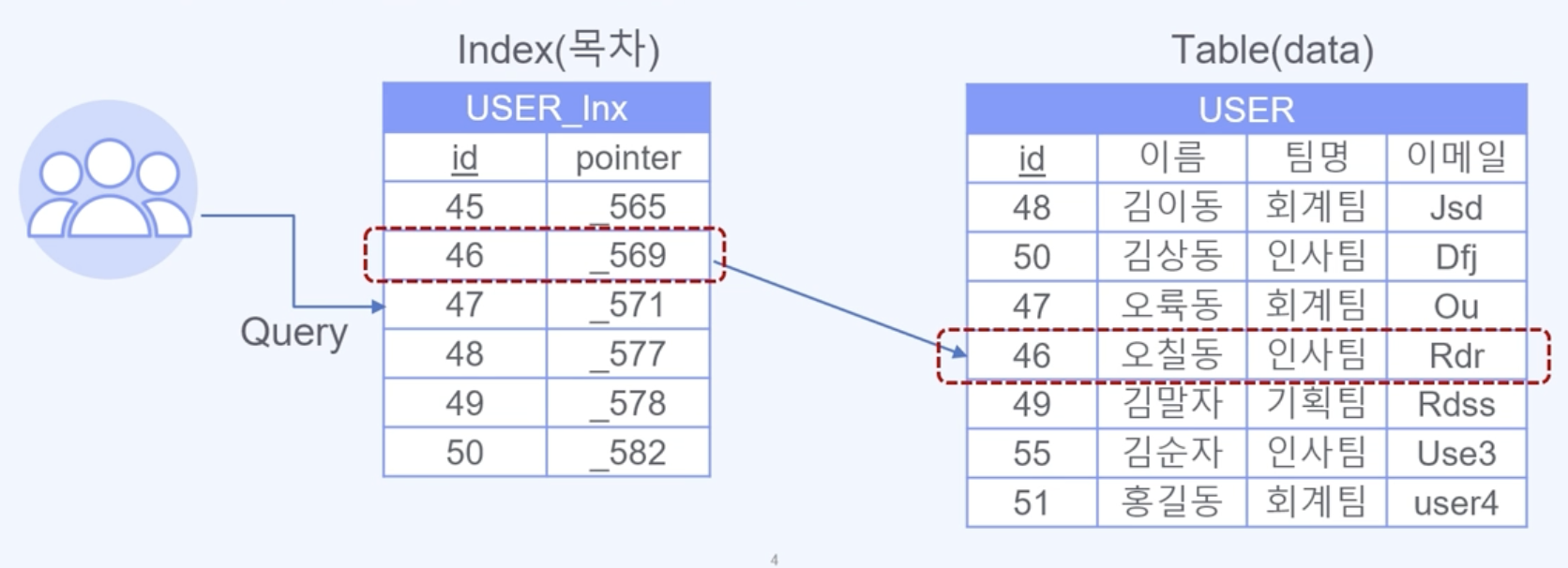
2. 인덱스 알고리즘
- 주로 B+트리 또는 B*트리 알고리즘으로 구현한다. 구체적인 것은 추후 자료구조 핵심 정리하면서 올려둘 예정.

3. 인덱스 사용 시 좋은 경우
- 데이터 규모가 큰 테이블
- 삽입, 수정, 삭제 작업이 자주 발생하지 않는 컬럼
- WHERE나 ORDER BY, JOIN 등이 자주 사용되는 컬럼
- 데이터 중복도가 낮은 컬럼 (= 분포도가 좋음)
4. 인덱스 사용 시 안 좋은 경우
- 데이터 규모가 작은 테이블
- 삽입, 수정, 삭제 작업이 자주 발생하는 컬럼
- 데이터 중복도가 높은 컬럼 (= 분포도가 나쁨)
- 추가적인 데이터 저장소가 필요 (= Cost 발생)
5. 인덱스 구조 방식
| 구조 | 설명 |
| 트리 기반 | • OLTP 범위 검색에 자주 사용 • B+트리, root/leaf 노드 구조 |
| 해시 기반 | • OLTP 키 검색에 자주 사용 • 버켓, 해시함수, 해시테이블 |
| 비트맵 기반 | • data warehouse, data mark 내 데이터 검색에 주로 사용 • 비트맵 인덱스 |
해시 기반

비트맵 기반

6. 인덱스 스캔 방식

- 만약 인덱스가 설정되어 있지 않다면, Full Scan을 하게 된다. 즉, 오래 걸린다.
- 인덱스가 설정되어 있으면, 만들어 놓은 인덱스 기반으로 굉장히 빠르게 탐색할 수 있다.
- 또한, Select에서 특정 컬럼만 조회할 때는 Fast Full index scan을 해서 더욱 빠르게 탐색한다.
7. 인덱스 스캔을 못 하는 경우
- 인덱스 스캔을 못 하는 경우에는 디스크/테이블 Full Scan을 수행하게 된다.
형변화
SELECT reg_date FROM table_name
WHERE TO_CHAR(reg_date, 'YYYYMMDD') = '20220317';
NULL / NOT NULL
SELECT column_name FROM table_name
WHERE column_name IS NULL
부정연산
SELECT column_name FROM table_name
WHERE column_name != 30; (NOT EXISTS)
Like연산
SELECT column_name FROM table_name
WHERE column_name LIKE '%S%';
OR조건
SELECT * FROM table_name1 t1, table_name2 t2
WHERE (t1.name1 = t2.name2 OR t1.name2 = t2.name2) and t1.code='1004';
'Computer Science > Database' 카테고리의 다른 글
| [Database] JDBC - DriverManager, Connection (MySQL 접속) (0) | 2023.01.13 |
|---|---|
| [JDBC] JDBC (Java Database Connectivity) (0) | 2023.01.12 |
| [데이터베이스 핵심 요약] 9. 반정규화(Denormalization) (0) | 2022.11.13 |
| [데이터베이스 핵심 요약] 8. 정규화(Normalization)와 함수적 종속성 (0) | 2022.11.13 |
| [데이터베이스 핵심 요약] 7. 데이터 무결성 (Data Integrity) (0) | 2022.11.12 |


